Introduction
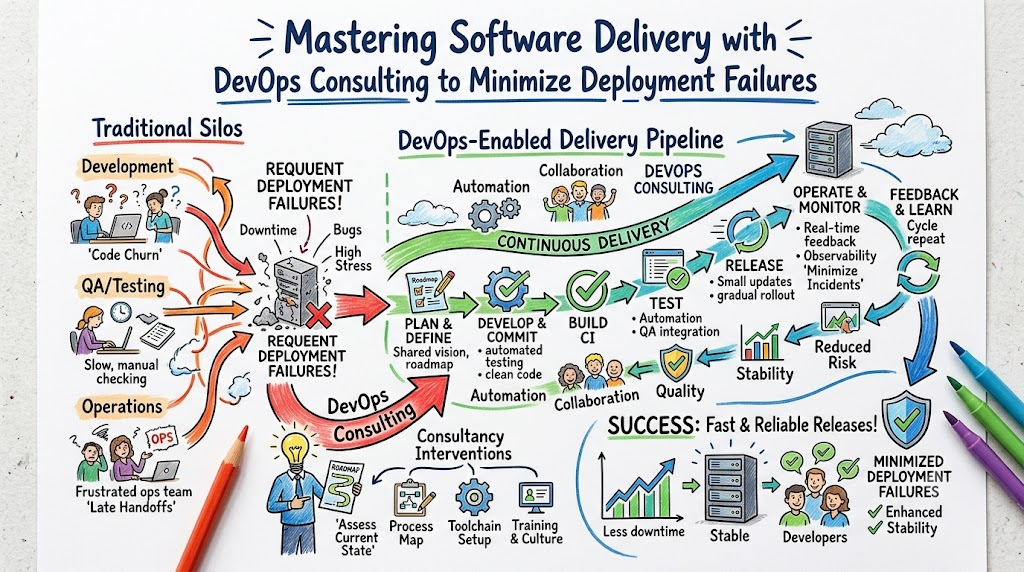
In the world of software development, nothing ruins a team’s morale faster than a failed deployment. You spend weeks coding, testing, and preparing for a release, only to watch the production environment crash the moment the new code goes live. It is a stressful, costly, and all-too-common scenario in organizations that rely on outdated or unrefined release processes. When production systems break, it is not just the developers who suffer; the business loses revenue, user trust erodes, and the engineering team gets stuck in a cycle of firefighting instead of innovating.
Many organizations find themselves trapped in this loop because they treat deployment as an afterthought rather than a critical engineering function. This is where professional guidance becomes transformative. When we look at how DevOps Consulting Reduces Deployment Failures, we are really looking at the shift from reactive troubleshooting to proactive system design. By partnering with experts from organizations like DevOpsSchool, companies can audit their internal workflows, implement rigorous automation, and cultivate a culture of reliability. In this guide, I will share the insights I have gathered over twenty years in the field about why deployments fail and how strategic consulting can help you regain control over your software delivery lifecycle.
What Is DevOps Consulting?
At its core, DevOps consulting is the practice of engaging external subject matter experts to assess, design, and optimize the way your organization builds, tests, and deploys software. It is not just about installing tools or buying software licenses. True DevOps consulting is about examining the gaps between your development, operations, and quality assurance teams.
A consultant acts as a bridge. They look at your current “way of working” and identify where human error, process bottlenecks, or technical debt are creeping into your pipeline. They help teams move away from manual “hand-offs” and toward a model of continuous delivery. It is a collaborative process where the goal is to standardize environments, automate repetitive tasks, and ensure that every release is predictable, repeatable, and, most importantly, successful.
Why Deployment Failures Happen
Deployment failures rarely happen because of a single “bad line of code.” They usually happen because of systemic issues that have been allowed to persist. In my experience, these are the most common culprits:
- Manual Deployment Steps: Relying on a human to manually execute scripts, copy files, or update configurations is the fastest way to invite error.
- Environment Mismatch: The code works on a developer’s laptop but fails in production because the configurations, library versions, or dependencies are different.
- Lack of Automated Testing: Without comprehensive unit, integration, and regression testing, bugs slip through to production unnoticed.
- Weak Rollback Planning: Teams often lack a “plan B.” When a deployment fails, they panic and try to “fix forward” in production, which usually makes the problem worse.
- Poor Monitoring and Visibility: Teams often find out about a deployment failure only after customers start complaining, rather than detecting it through real-time observability.
Business Impact of Deployment Failures
When deployments fail, the impact ripples through the entire company. It is not just a technical issue; it is a financial and operational one.
| Deployment Problem | Business Impact |
| Extended Downtime | Direct loss of revenue and potential SLA penalties. |
| Frequent Hotfixes | Redirects engineers from product development to emergency patching. |
| Customer Churn | Users lose confidence in the stability of the platform and may switch to competitors. |
| Increased Stress | High pressure on the engineering team leads to burnout and high turnover. |
| Security Vulnerabilities | Rushed, manual patches often bypass security protocols, leaving systems exposed. |
How DevOps Consulting Reduces Deployment Failures
When a consultancy is brought in, they do not just implement tools; they implement a methodology. The objective is to stabilize the release pipeline so that failure becomes an anomaly rather than a routine event.
| Consulting Area | Deployment Improvement |
| CI/CD Pipeline Optimization | Eliminates manual errors by automating the entire delivery flow. |
| Infrastructure Standardization | Ensures production environments mirror development, removing “works on my machine” issues. |
| Testing Strategy | Shifts testing to the left, catching bugs before they reach the production environment. |
| Monitoring and Observability | Provides real-time insights, allowing for proactive detection of anomalies. |
| Incident Response Planning | Ensures there is a clear, automated path to rollback if a deployment fails. |
Area #1: CI/CD Pipeline Optimization
Continuous Integration and Continuous Deployment (CI/CD) is the heartbeat of modern DevOps. Consultants look at your current pipeline—likely a mess of fragmented scripts—and restructure it into a unified, automated flow.
The Workflow:
A consultant will help you implement tools like Jenkins, GitLab CI, or GitHub Actions. They will configure your pipeline so that every code commit triggers a series of automated checks. If a test fails, the pipeline stops immediately, preventing broken code from ever being packaged for deployment. This creates a “fail fast” mechanism where developers get immediate feedback, allowing them to fix issues in minutes rather than hours.
Area #2: Better Testing Strategies
Many teams rely on manual QA testing, which is slow and prone to human error. A consultant will guide you toward implementing “Shift-Left” testing. This means moving security and quality checks to the very beginning of the development cycle. They will help you automate unit tests, integration tests, and security scans. By the time code reaches the final staging area, it has already been verified for functionality, performance, and basic security compliance.
Area #3: Infrastructure Standardization
One of the most common reasons for deployment failure is “configuration drift,” where servers or cloud environments evolve differently over time. Consultants introduce Infrastructure as Code (IaC) using tools like Terraform or Ansible. Instead of manually configuring servers, you define your infrastructure in code files. This ensures that your production environment is an exact, version-controlled clone of your staging and development environments. If you can replicate your environment exactly, you eliminate 90% of environment-related deployment failures.
Area #4: Monitoring and Observability
You cannot fix what you cannot see. Consultants help teams implement robust observability stacks using tools like Prometheus and Grafana. They do not just set up dashboards; they define “Service Level Indicators” (SLIs) and “Service Level Objectives” (SLOs). This means that during a deployment, the team has a clear view of error rates, latency, and CPU usage. If an anomaly is detected, automated alerts notify the team instantly.
Area #5: Faster Incident Recovery
Even with the best processes, failures can happen. The difference between a minor blip and a major disaster is the ability to recover. Consultants help implement “blue-green deployments” or “canary releases.” In a blue-green scenario, you have two identical production environments. You deploy to one, test it, and if it fails, you simply switch traffic back to the original environment in seconds. This reduces your Mean Time To Recovery (MTTR) from hours to seconds.
Real-World Example: Team Without DevOps Consulting
Consider a mid-sized e-commerce company that releases updates once a month. The process is entirely manual:
- Developers email a list of changes to the Operations team.
- The Ops team manually copies files to the production server on a Friday night.
- The database migration is run by hand.
- If the site crashes, the team spends all Saturday morning rolling back the changes.
- There is no documentation, so the rollback takes 6 hours.
This team is trapped in a cycle of fear. They dread deployments, and because they dread them, they do them less often. This leads to larger, riskier releases, which increases the likelihood of failure. It is a self-fulfilling prophecy.
Real-World Example: Team Using DevOps Consulting
Now, look at a similar company that engaged a DevOps consultancy.
- They implemented an automated CI/CD pipeline.
- The developers push code, and the pipeline runs automated tests.
- The deployment is triggered automatically using a deployment tool.
- Infrastructure is provisioned via Terraform.
- If the new version shows high error rates (tracked by Prometheus), the system automatically triggers a rollback to the previous version.
- The entire process is visible on a dashboard, and the team is notified via Slack.
The result? The team now releases updates daily with minimal risk. If a failure occurs, it is caught automatically, and the system reverts itself without manual intervention.
Common Deployment Mistakes Organizations Make
In my experience, teams often fall into the same traps when trying to improve their deployment processes:
- Trying to automate everything at once: You cannot automate a broken process. Clean up the process first, then automate.
- Ignoring cultural shifts: Tools are useless if the culture is still silos-based. Developers and Ops must work together.
- Relying on “Hero Culture”: Depending on one or two senior engineers to manually “save” the deployment is not a strategy; it is a risk.
- Skipping documentation: Even automated systems need documentation so new team members understand the logic behind the pipeline.
Common Beginner Misunderstandings
There are several myths that beginners often believe about DevOps consulting. Let’s clear those up.
- Myth: Automation eliminates all failures.
- Reality: Automation eliminates manual errors. It can also catch logical errors if the tests are good. But it does not eliminate architectural flaws or design errors.
- Myth: CI/CD guarantees success.
- Reality: CI/CD is a delivery mechanism. If you feed it bad code and poor tests, it will just deliver failure faster.
- Myth: Consultants only recommend tools.
- Reality: Tools are the easiest part. Consultants focus more on the “why” and “how”—the workflows and the mindset.
- Myth: Monitoring is only for after the release.
- Reality: Observability starts at development. You should be monitoring your integration tests just as closely as your production environment.
Best Practices for Reducing Deployment Failures
If you are looking to stabilize your deployments, start with this checklist:
- Implement Version Control for Everything: Code, configuration, and infrastructure.
- Automate Testing: Aim for 80%+ coverage for critical paths.
- Small, Frequent Releases: Break large releases into small, manageable chunks. The smaller the change, the easier it is to troubleshoot.
- Standardize Environments: Use containerization (like Docker and Kubernetes) to ensure consistency.
- Define Clear Rollback Procedures: Never deploy without an “undo” button.
- Conduct Post-Mortems: When a failure happens, do not blame individuals. Analyze the process and update the system to prevent recurrence.
Role of DevOpsSchool in Learning DevOps Consulting
Understanding the nuances of DevOps consulting requires more than just reading; it requires hands-on experience and exposure to real-world engineering environments. This is where DevOpsSchool plays a pivotal role. They provide a structured learning path that goes beyond theoretical concepts, focusing on the actual CI/CD pipelines, automation tools, and monitoring strategies that are essential for minimizing deployment failures. By engaging with their resources, aspiring engineers and teams can gain the practical skills needed to design, implement, and maintain reliable software delivery systems that stand up to the demands of modern enterprise IT.
Career Importance of DevOps Consulting Skills
The demand for professionals who understand how to reduce deployment failures is skyrocketing. Roles like DevOps Engineer, Site Reliability Engineer (SRE), and Platform Engineer are central to the digital economy.
The core skills—mastery of CI/CD, cloud architecture, infrastructure as code, and observability—are highly transferable. If you can prove that you know how to build a system that fails gracefully and recovers automatically, you become an invaluable asset to any organization. It is not just a job; it is a skillset that defines the reliability of the entire internet.
Industries Benefiting from DevOps Consulting
While every tech company needs this, some industries have zero tolerance for failure:
- Banking and Finance: Where a single failed deployment can result in massive financial loss and regulatory fines.
- Healthcare: Where uptime can literally be a matter of life and death, and data integrity is paramount.
- SaaS Platforms: Where constant innovation is required, but downtime drives customers to competitors.
- E-Commerce: Where every minute of downtime during peak traffic translates to lost revenue.
- Telecom: Where global connectivity must remain uninterrupted, requiring incredibly complex deployment strategies.
Future of DevOps Consulting
The future of this field is moving toward “Self-Healing Infrastructure.” We are seeing the rise of AI-assisted deployment automation, where systems don’t just alert us to a problem; they analyze the logs, identify the root cause, and suggest—or even execute—the fix.
Platform Engineering is also becoming a major trend, where the focus shifts to creating internal developer platforms that “pave the road” for developers, making it impossible to deploy incorrectly by default. DevOps consulting will increasingly be about building these platforms that bake reliability into the foundation.
FAQs
- Why do deployment failures happen so often in large companies?They usually happen because of “too many cooks.” Siloed teams, manual hand-offs, and lack of standard environments create a complex system where things easily break.
- How does DevOps consulting actually help?It helps by introducing discipline, standardization, and automation, turning a chaotic process into a predictable engineering workflow.
- Can automation completely prevent failures?Not completely, but it reduces the blast radius. You can catch errors earlier and recover faster, which is the next best thing to preventing them.
- Why is monitoring considered a part of deployment reliability?Because you need to verify if the deployment was actually successful. Without monitoring, you are flying blind.
- What are the best tools for deployment reliability?Tools like Jenkins, GitLab CI, Terraform, Kubernetes, Prometheus, and Grafana are the industry standard for building a reliable delivery pipeline.
- Can a beginner really learn these consulting concepts?Absolutely. It starts with learning the fundamentals of CI/CD and infrastructure as code, then scaling that knowledge through practice.
- Why does CI/CD matter for reducing failures?It enforces a “pipeline” that tests code at every stage, preventing untested code from reaching production.
- What exactly is “rollback planning”?It is having a predefined, tested, and automated way to revert to the previous stable version of your software instantly if something goes wrong.
- Is DevOps consulting expensive?The cost of consulting is almost always less than the cost of a major production outage. It is an investment in stability.
- Do I need to be a developer to understand this?You need to understand the development workflow, but you don’t necessarily need to be a coder. A deep understanding of operations and processes is equally valuable.
- How do I measure the success of a DevOps engagement?Look at your “Deployment Frequency” and “Change Failure Rate.” If the former goes up and the latter goes down, you are winning.
- Is DevOps consulting only for cloud-native companies?No, it is for anyone building software. Even on-premise legacy systems benefit immensely from CI/CD and automation.
- What is the difference between SRE and DevOps consulting?SRE (Site Reliability Engineering) is a specific implementation of DevOps principles focused on reliability. A consultant helps you get there.
- Why is infrastructure as code (IaC) so important?It treats your server configuration just like software code, allowing for versioning, testing, and easy reproduction of environments.
- How long does it take to see results from DevOps consulting?You can see quick wins in weeks, but cultural and systemic transformation usually takes months.
Final Thoughts
Reducing deployment failures is not about achieving perfection. It is about creating a system that can withstand change. When we talk about how DevOps consulting reduces deployment failures, we are talking about building resilience. By automating the mundane, standardizing the environment, and prioritizing visibility, you remove the fear from the release process.
This path requires discipline. It requires a commitment to continuous learning and a willingness to change how things have “always been done.” Whether you are a developer, a team lead, or an organization leader, understand that stability is a choice you make through your process. Start small, automate one manual step at a time, and never stop monitoring your delivery pipeline.
Best Cardiac Hospitals Near You
Discover top heart hospitals, cardiology centers & cardiac care services by city.
Advanced Heart Care • Trusted Hospitals • Expert Teams
View Best Hospitals